Blog > Introduction to Apache Kafka

Apache Kafka is an open-source publish/subscribe messaging system. It is a distributed event log where all the new records are immutable and appended to the log’s end. In Kafka, messages may persist on disk for a specific period known as the retention policy; this is usually the main difference between Apache Kafka and other messaging systems and makes Kafka in some way a hybrid between a messaging system and a database.
Apache Kafka’s central concept is producers producing messages on different topics and consumers consuming those messages and maintaining the data stream. A user can think about producers as publishers or senders of messages. On the other hand, consumers are analogous to the receivers or subscribers.
Why Apache Kafka
Apache Kafka aims to provide a reliable and high throughput platform for handling real-time data streams and building data pipelines. It also provides a single place to store and distribute events that can accumulate into multiple downstream systems, fighting the ever-growing integration complexity problem. Kafka is popular to build a modern and scalable ETL (Extract Transform Load) change data capture or big ingest systems.
It is useful across multiple industries, from companies like Twitter and Netflix to Goldman Sachs and Paypal.
Kafka Architecture
Apache Kafka architecture is consists of a high-level Kafka cluster, producers, and consumers. A single Kafka cluster is also famous as a broker. Its cluster usually consists of at least three brokers to provide redundancy. These brokers are responsible for receiving messages from producers, assigning offsets, and committing messages to the disk. It is also responsible for responding to consumers’ fetch requests and serving messages. In Kafka, when messages deliver to abroker, they are sent to a particular topic.
Topics: Topics provide a way of categorizing data that is delivered, and they can further break down into several partitions; for example, a system can have separate topics for processing new users, and for processing metrics, each partition as a separate commit log and the order of messages is guaranteed only across the same partition.
Splitting a topic into multiple partitions makes scaling easy as a separate consumer can read each partition. For achieving high throughput as both partitions, and consumers can split across multiple servers.
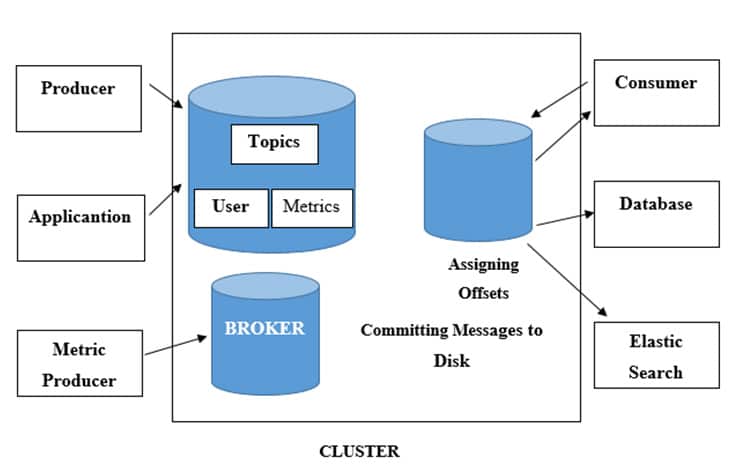
Producers are usually other applications producing data; this can be, for example, our application producing metrics and sending them to our Kafka cluster; similarly, consumers are generally other applications consuming Kafka data.
Kafka often acts as a central hub for all events in the system, which means it is a perfect place to connect. If a user is interested in a particular type of data, a good example would be a database that can consume and persist messages or an elastic search cluster that can consume certain events and provide full-text search capabilities for other applications.
Messages in Kafka and Data Model
In Apache Kafka messages, a single unit of data can send or received as far as Kafka is concerned; a message is just a byte array. A message consists of an optional key and byte array to write data in a more controlled way to multiple partitions within the same topic.
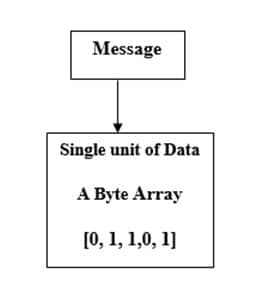
The Apache Kafka data model consists of messages and topics.
- Messages represent text in a log file, stock market data, or an error message from a system.
- Messages are categories into topics, for example, LogMessage and StockMessage.
- Producers are the processes in Kafka to publish messages into a topic.
- The processes that receive messages from a topic in Kafka are popular as consumers.
- Kafka’s processes or servers that are using to process the messages are known as brokers.
- A Kafka cluster consists of a set of brokers that process the messages.
Kafka Use Case
Apache Kafka is useful for various purposes in a business organization, such as:
Messaging Service: Kafka messaging service allows us to send and receive millions of messages in real-time.
Real-Time Stream Processing: Kafka can process a continuous stream of information in real-time and pass it to stream processing systems such as Strom.
Log aggregation: Kafka can collect physical log files from multiple systems and store them in a central location such as HDFS.
Commit Log Service: Kafka is useful as an external commit log for a distributed system.
Event Source: A time-ordered sequence of events can maintain through Kafka.
Author: SVCIT Editorial
Copyright Silicon Valley Cloud IT, LLC.