Blog > Introduction to Recommender System

What is a Recommender System?
A recommender system is an unsupervised machine-learning algorithm. It’s an automated system to filter some entities. These entities can be any products, ads, people, movies, or songs, and we see this technology at Amazon to Netflix, Pandora, YouTube, and eHarmony. For example, when a user watches a movie, they will get recommendations for other related movies on their screen based on the power of previous viewing history. It can also be a product that users bought, and then they will get a recommendation for another product based on the last viewing product or purchase history.
A recommender system can build either by finding questions that a user may be interested in answering, or based on the questions answered by other users like him finding other questions similar to the questions he answered already.
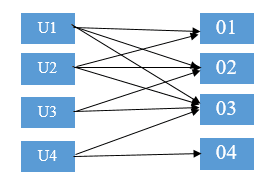
The recommender doesn’t work only in what products we are being shown and in what order the products are being ranked. It is an effective technique in terms of business because Google, Facebook, and Amazon are all big companies using powerful recommendation systems to expand their business by determining the users’ interests.
Why Need a Recommender System Built?
Businesses are showing us recommendations and relevant content for a couple of reasons. Most businesses think they understand their customer, but often customers can behave much differently than they would think. Hence, it’s essential to show the users what is relevant to them while also sharing new items they would be interested in.
Recommender systems also help solve the information overload problem and help us narrow down the set of choices. For businesses, they benefit from selling more relevant items to the user.
It also helps customers to discover new and interesting things and help to save time. From a business perspective, it helps to understand better what the user wants. Similarly, user reviews, ratings, and relevancy can play a factor in terms of what is being recommended to customers.
How Does the Recommender System Work?
When a customer purchases a product online, the recommendation engine will ask the customer what they want or ask if the content is relevant, look at another user with similar behaviour, or study the customer’s activity.
For example, when a user goes to Netflix or any other service that relies on recommendations, the first time when a user visits there they will ask what their taste preferences are, and there is a reason for that; if they do not know what is their customers taste preferences are at all, they have no idea what their customers’ need. They have no profile for the customer. It’s a “Cold Start Problem.”
Types of Recommender Systems
There are three types of recommender systems such as:
Content-Based Filtering
Recommend items based on the browsing or purchase history in the past or based on the content of items rather than other users’ opinions.
User Profiles: Create user profiles to describe the types of items that the user prefers (e.g., correlations among items).
Recommendations based on keywords are also classified as content-based.
Advantages
- No need for data on other users, no “Cold Star Problem” and sparsity.
- Able to recommend users with unique tastes.
- Able to recommend new and unpopular items.
Limitations
- Data should be in a structured format.
- Unable to use quality judgments from other users.
Collaborative Filtering
Recommend items based on the interests of a community of users. This method finds a subset of users who have similar tastes and preferences to the target user recommendations.
Basic Assumptions
- Users with similar interests have common preferences.
- A sufficiently large number of user preferences are available.
Main Approaches
There are two main approaches in collaborative filtering: User-Based filtering and Item-Based Filtering.
User-Based
- Use a user-item rating matrix.
- Make user-to-user correlations.
- Find highly correlated users.
- Recommend items preferred by those users.
Advantages
- No knowledge about item features is needed.
Problems
- New user “cold start problem.”
- New item “cold start problem”: Items with few ratings can not easily be recommended.
Sparsity Problem
If there are many items to be recommended, the user/ rating matrix is sparse, and it is hard to find the users who have rated the same item.
Popularity Bias
Tend to recommend only popular items.
Item-Based
- Use a user-item rating matrix.
- Make item-to-item correlations.
- Find highly correlated items.
- Recommend items with the highest correlation.
Advantages
- No knowledge about item features is needed.
- Better scalability because of correlations between a limited number of items instead of a huge number of users.
- Reduce the sparsity problem.
Problems
- New user “Cold Start Problem.”
- New item “Cold Start Problem,” e.g., Amazon, eBay.
Hybrid Content-Based Collaborative Filtering
Hybrid is a combination, content-based, and collaborative filtering approach to overcome the disadvantages of each approach.
Recommendation Algorithms
- User-based Collaborative Filtering
- Item-based Collaborative Filtering
- Slope One Recommenders
- Singular Value Decomposition
Recommendation Engines
Implementation | Key Parameters | Key Features |
| Generic user-based recommender | · User similarity metric. · Neighborhood definition and size. | · Conventional implementation. · Fast when the number of users is relatively small. |
| Generic Item Based Recommender | · Item similarity metric. | · Fast when the number of items is relatively small. · Useful when an external notation of item similarity is available. |
| Slop One Recommender | · Different storage strategies. | · Recommendations and updates are fast at runtime. · It requires a large re-computation. · Suitable when the number of items is relatively small. |
| SVD Recommender | · Number of Features | · Good results. · It requires large pre computations. |
| KNN Item Based Recommender | · Number of means (k) · Item similarity metric. · Neighborhood size. | · Recommendations are fast at runtime. · It requires large precomputation. · Good when the number of users is relatively small. |
Non-Personalized Recommendation
As a person begins to browse a few pages, the engine determines a person’s preferences and leverages this information to offer tailored recommendations.
Data Acquisition
- User Shopping card activities.
- The user purchasing activities.
- User favorite items profile (i.e., Wish List).
Processing Model of Recommendation Engine
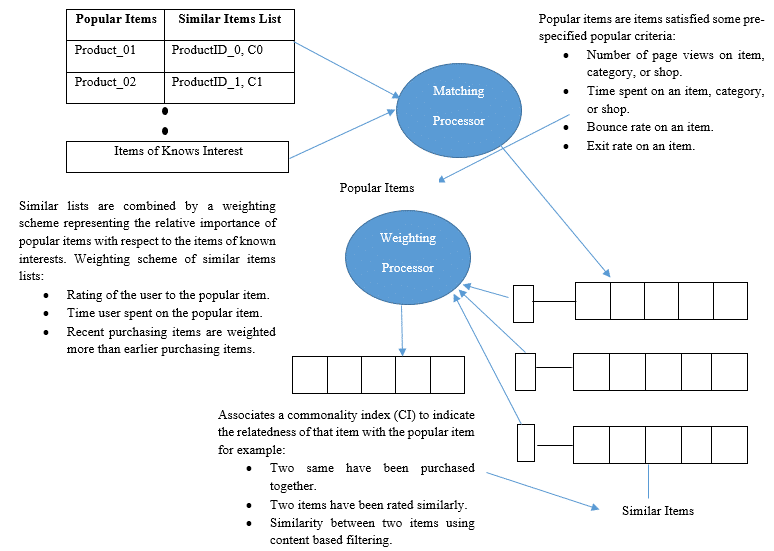
Author: SVCIT Editorial
Copyright Silicon Valley Cloud IT, LLC.