Blog > What is AWS Data Pipeline Service?
Data is growing exponentially at a rapid pace. Companies of all sizes realize that managing this data is a more complicated and time-consuming process.
Problem Statement
Massive amounts of data are in different formats, so processing, storing, and migrating data becomes complex. Companies have to manage various types of data such as:
- Real-time data for registered users.
- Web server logs for potential users.
- Demographic data and login credentials
- Sensor data and third party datasets
Depending on the need for data, maybe companies store their data at different data stores. They may store real-time data into DynamoDB, bulk data in Amazon S3, and store sensitive information in Amazon RDS. So processing, storing, and migrating data from multiple sources become more complex.
Feasible Solution
The feasible solution is to use different tools to process, transform, analyze and migrate the data.
Optimal Solution
The optimal solution for this problem is a data pipeline that handles processing, visualization, and migration. Data pipeline also makes it easy for the users to integrate that is spread across different data sources. It also transforms, processes, and analyses data for the company at the same location.
AWS Data Pipeline
Amazon web services offer a data pipeline service called AWS data pipeline. AWS data pipeline is a web service that helps users reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals. It helps to easily access data from various locations, transform and process it at scale, and then transfer the results to the other AWS services such as S3, Dynamodb, or its cloud on-premise data store.
Using AWS Data Pipeline, the user can archive their web server logs to the Amazon S3 bucket daily and then run the EMR cluster over these logs to generate on a weekly basis.
The data pipeline concept is straightforward. To begin with, the user needs AWS Data Pipeline sitting on top, input data stores like Amazon S3, Redshift, or Dynamodb, etc. Data from these data stores is pass to the AWS pipeline, where it will process, analyze, transform according to user need; analysis results are put into data stores. The output data stores can be S3 bucket, Dynamodb table, etc.
Benefits of AWS Data Pipeline
- Provides drag and drop console.
- It is built on distributed, reliable infrastructure.
- Supports scheduling and error handling.
- Complete control over the computational resources.
- Inexpensive to use.
- Distribute work to one machine or many.
Components of AWS Data Pipeline
It has three components to work together to manage data.
1. Pipeline Definition
An organization has to communicate business logic to the AWS Data Pipeline service.
Data Nodes: It contains different services, such as it has data nodes; the data nodes are nothing but the names, locations, and formats of data sources.
Activities: It also has activities that transform the data, such as moving data from one source to another or performing queries on the data.
Schedules: The user can schedule their activities.
Preconditions: The user also sets preconditions that must be satisfied before scheduling their activities.
Resources: It has computed resources like Amazon EC2 instances or Amazon EMR clusters.
Actions: Actions update users about the status of their data pipeline. For example, it will send a notification to their email or trigger an alarm, etc.
2. Pipeline
Pipeline offers to schedule and runs tasks to perform defined activities. It has three-part such as:
- Pipeline Components
- Instances
- Attempts
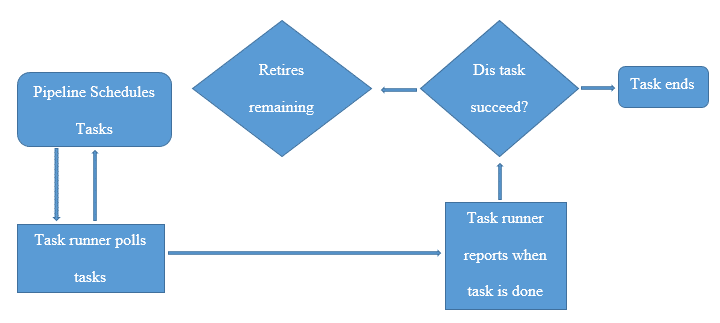
3. Task Runner
Task runner is an application that pulls AWS Data Pipeline for tasks and then performs those tasks.
Author: SVCIT Editorial
Copyright Silicon Valley Cloud IT, LLC.