Blog > How to Integrate Neo4J with Apache Kafka

Apache Kafka
Apache Kafka is a distributed stream platform built on three capabilities:
- Publish and subscribe to streams of records.
- Store a stream of records in a fault-tolerant durable way.
- Process streams of records as they occur.
How does Apache Kafka Works?
Topics: A topic is a category or feed name to which records can publish.
Partitions: For each topic, the Kafka cluster maintains a partitioned, distributed persistent log.
How is Apache Kafka Used?
Organizations generally use Kafka for two classes of applications:
- Building real-time streaming data pipelines.
- Building real-time streaming applications.
What are Neo4j Streams?
It’s a Neo4j plugin that enables Kafka to stream on Neo4j. The project is composed of two plugins. The first one is the Neo4j plugin that must be installed in Neo4j. It provides three features such as:
- The change data capture
- Neo4j Streams Sink
- Neo4j Stream procedures
It also provides Kafka connect sink plugin. If the user chooses Kafka to connect the plugin, then it only provides the sink module.
Benefits of Neo4j Integration with Kafka
- Avoid custom “hacky” solutions.
- Deployed by Neo4j field engineering
- Used by many customers
- Continuous development
- Quick response to issues
- Officially (enterprise) supported by Confluent and Neo4j through Larus.
Neo4j – Kafka Integration – Use Cases
How can it be used?
- Write/read data directly from Neo4j operations to Kafka.
- Change data capture stream graph changes into larger architectures, e.g., to feed microservices or other databases.
- Exchange data/updates between distinct Neo4j installations, e.g., from analytics.
- Integrate with existing Kafka architecture of customers.
- Also, use other Kafka connectors to offer more Neo4j integrations.
- Build just-in-time data warehouses with Spark and Hadoop.
Neo4j Streams: Change Data Capture (CDC)
What is CDC?
In the database, Change Data Capture (CDC) is a set of software design patterns used to determine (and track) the data that has changed so action can be taken using the changed data.
- CDC solutions occur most often in data-warehouse environments.
- Allows replicating the database without having much performance impact on its operation.
How CDC Works?
Each transaction communicates its changes to our event listener:
- Exposing creation, updates, and deletes of Nodes, Relationships, and Properties.
- CDC is providing before and after information.
- Provide schema information.
- Its configuring property is filtering for each topic.
- Those events are sent asynchronously to Kafka so that the commit path is not influenced by that.
Neo4j Stream: Sink
Ingest Data
The sink provides several ways to ingest data from Kafka, such as:
- Ingestion of data via Cypher Template.
- Via CDC event published by another Neo4j instance via the CDC module.
- Via projection of a JSON / AVRO event into Node / Relationship by providing an extraction pattern.
- It’s using CUD file format.
How does Neo4j Stream Manage Bad Data?
The Neo4j streams sink module provides a dead letter queue mechanism that, if activated, re-routes all “bad-data” to a configured topic.
Neo4j Stream: Procedures
The user can directly interact with Apache Kafka from Cypher. The Neo4j stream project comes out with two procedures:
Streams-Publish: Allows custom message streaming from Neo4j to the configured environment by using the underlying configured producer.
Stream, consume: This allows consuming messages from the given topic.
Confluent Connect Neo4j Plugin
The second plugin is the Kafka Connect plugin. It is an open-source component of Apache Kafka that connects Kafka with external systems such as databases, key-value stores, search indexes, file systems like HTFS, etc.
It works exactly like the Neo4j Sink plugin to provide each topic for the users’ ingestion setup.
UseCase
Real-time Polyglot Persistence with Elastic, Kafka, and Neo4j
First, we need to ingest data into Elastic and Neo4j from a Kafka topic. Then, the user needs to prepare a fake data generator that emits records to Kafka. It allows emitting records over two topics: one for personal info records and one for movies.
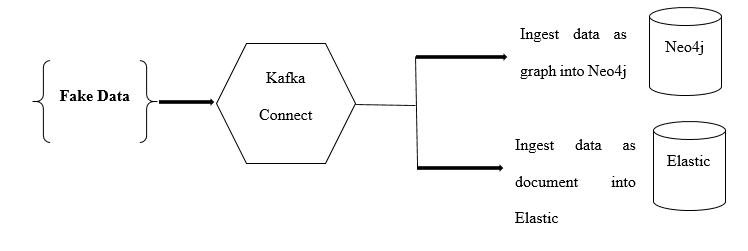
First, it will create a fake database; suppose the fake database is based on famous movies recorded in the Neo4j ecosystem, and from the same two topics, we will ingest data. Finally, we will ingest the data as a graph into Neo4j, and we will ingest the data into Elastic as indexes.
In the second step, the user needs to use Neo4j to run the page rank over the graph. To find the most influential actors over the network and the result, the scope used by this page rank computed via the graph algorithms library are published to a new Kafka topic. So, on the other side, the Kafka sink that insists on a new topic will update the data into Elastic with the score of the page rank computation because we can provide a search feature for instances where the records are recorded by the page rank computation.
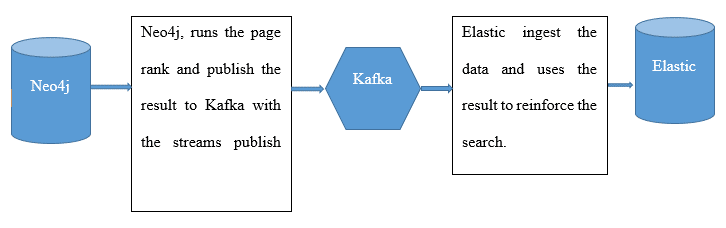
(Neo4j emitting data to Elastic through Kafka )
Author: SVCIT Editorial
Copyright Silicon Valley Cloud IT, LLC.